

Authors:
(1) Bo Wang, Beijing Jiaotong University, Beijing, China ([email protected]);
(2) Mingda Chen, Beijing Jiaotong University, Beijing, China ([email protected]);
(3) Youfang Lin, Beijing Jiaotong University, Beijing, China ([email protected]);
(4) Mike Papadakis, University of Luxembourg, Luxembourg ([email protected]);
(5) Jie M. Zhang, King’s College London, London, UK ([email protected]).
Table of Links
3 Study Design
3.1 Overview and Research Questions
3.3 Mutation Generation via LLMs
4 Evaluation Results
4.1 RQ1: Performance on Cost and Usability
4.3 RQ3: Impacts of Different Prompts
4.4 RQ4: Impacts of Different LLMs
4.5 RQ5: Root Causes and Error Types of Non-Compilable Mutations
5 Discussion
5.1 Sensitivity to Chosen Experiment Settings
4 EVALUATION RESULTS
We performed our experimental analysis on two cloud servers, each of which is equipped with 2 NVIDIA GeForce RTX 3090 Ti, 168GB memory, and a 64 Core CPU Intel(R) Xeon(R) Platinum 8350C.
4.1 RQ1: Performance on Cost and Usability
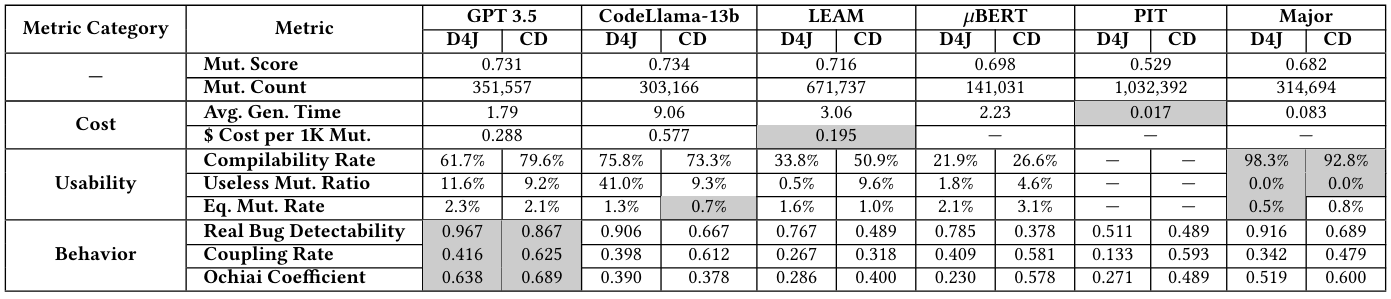
4.1.1 Cost. For each technique, we record the generation duration and the cost for API usage or rending GPU servers, shown as the Cost lines of Table 4. In addition, we also report the mutation count and mutation score, although they do not fully reflect the overall quality of the mutation set.
From the table, we can find that GPT-3.5 and CodeLlama-30bInstruct generate 351,557 and 303,166 mutations[1], with a mutation score of 0.731 and 0.734, respectively. Traditional approaches PIT and Major yield the lowest mutation score among all the approaches.
In terms of cost, GPT-3.5 and CodeLlama-13b cost 1.79s and 9.06s to generate mutations, respectively. While LEAM, 𝜇Bert, PIT, and Major cost 3.06s, 2.23s, 0.017s, and 0.083s, respectively, indicating that previous approaches are faster than LLM-based approaches in generating mutations. In terms of economic cost, we only record the API usage cost of GPT-3.5 and the cloud server cost for running CodeLlama and LEAM, because the remaining approaches barely need GPU resources. The result indicates that renting cloud servers to run the open-source models costs more than using API for GPT3.5.

4.1.2 Mutation Usability. The usability of mutations (i.e., whether the mutations can be used to calculate mutation score) is affected by the capabilities of LLMs in correctly understanding the task and generating compilable, non-duplicate, and non-equivalent mutations. The results are shown as the Usability rows in Table 4. Due to the potential threat of data leakage, we represent the data of Defects4J and Condefects separately. Note that the mutations of PIT are in the form of Java bytecode and cannot be transformed back to the source level, so we skip PIT when answering this RQ.
Compilability Rate: We observe that GPT-3.5 achieves a compilability rate of 61.7% for Defects4J and 79.6% for ConDefects datasets. While CodeLlama-13b achieves a higher compilability rate of 75.8% for Defects4J and 73.3% for ConDefects. The rule-based approach Major achieves the highest compilabity rate (i.e., 98.3% on Defects4J and 92.8% on ConDefects). Note that though Major operates under simple syntax rules, it can still generate non-compilable mutants. For example, the Java compiler’s analyzer rejects constructs like while(true)
Useless Mutation Rate: We also observe that LLMs generate a significant portion of duplicate and useless mutations. For example, for Defects4J, GPT-3.5 generates 11.6% useless mutations, accounting for 18.8% of all compilable mutations (i.e., 11.6%/61.7%). In contrast, LEAM, 𝜇Bert, and Major seldom generate duplicate mutations, which is likely due to these approaches being governed by strict grammar rules that limit the production of redundant mutations. For example, Major iteratively applies different mutation operators producing no redundant mutants.
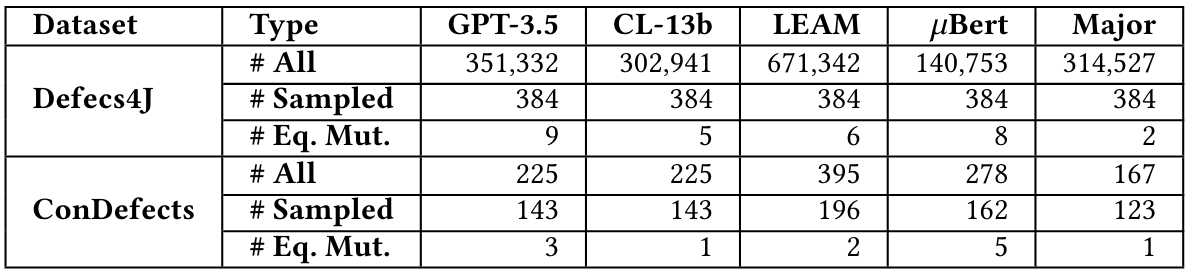
Equivalent Mutation Rate: Equivalent mutations change the source code syntactically without affecting the program’s functionality, thereby affecting the accuracy of mutation score calculations. Due to the undecidable nature of identifying equivalent mutations, it is not feasible to design an algorithm that can completely detect them. Therefore, we sample a subset of mutations for each technique and manually assess whether they are equivalent. To maintain a 95% confidence level and a 5% margin of error, we sampled a fixed number of mutations from each approach’s output, to calculate the Equivalent Mutation Rate. Following the protocol of existing studies [26, 31], two authors, each with over five years of Java programming experience, first received training on the equivalent mutants, and then independently labeled the mutations. The final Cohen’s Kappa coefficient score [75] is more than 90%, indicating a high level of agreement. Table 5 shows the number of sampled mutations and the number of identified equivalent mutations.
We again observe that Major performs the best in generating non-equivalent mutants. In particular, as shown in the bottom row of Usability section in Table 4, for GPT-3.5, 2.3% of mutations generated on Defects4J are equivalent, while the rate is 2.1% on ConDefects. CodeLlama-13b shows lower rates, with 1.3% and 0.7% on Defects4J and ConDefects, respectively. LEAM generates equivalent mutations at rates of 1.6% on Defects4J and 1.0% on ConDefects. 𝜇Bert produces 2.1% on Defects4J and 3.1% on ConDefects. Major achieves the lowest rates, with only 0.5% on Defects4J and 0.8% on ConDefects.
When comparing the two datasets Defects4J and ConDefects for the three usability aspects introduced above, we observe that the metrics vary between the Defects4J and ConDefects datasets for each mutation approach. This variation may be attributed to differences in the complexity and structure of bugs present in each dataset. Mutations in Defects4J may involve APIs and global variables that are not explicitly mentioned in prompts, making the
context more complex. This complexity results in both metrics being inferior on Defects4J compared to ConDefects.

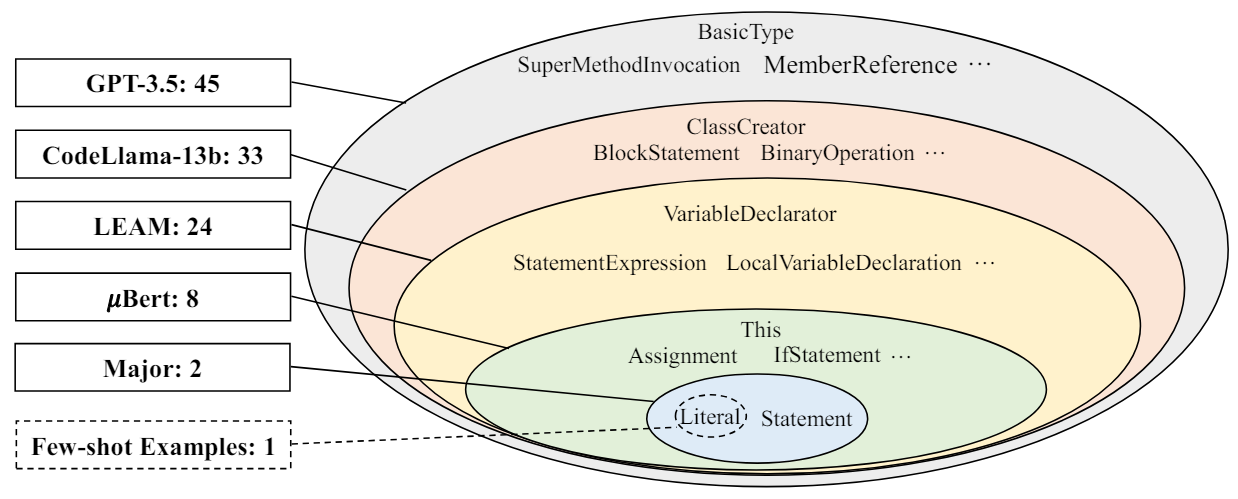
Figure 2 shows the results, which reveal that LLM-based mutation approaches introduce more types of new AST nodes than other approaches. GPT-3.5 exhibits the greatest diversity, introducing 45 new AST node types, and subsuming all other approaches. Traditional approach Major introduces only two new types of AST
nodes, which is not surprising as the mutation operators are a fixed set of simple operations.
We also check the AST node diversity of the examples we provided in the LLM prompts (see Table 3), as shown by the “Few-shot Example” in Figure 2. Interestingly, we find that these examples introduce only one new type of AST node. This indicates that the LLMs are creative in generating mutations, producing significantly more diverse mutations than the examples provided to them.
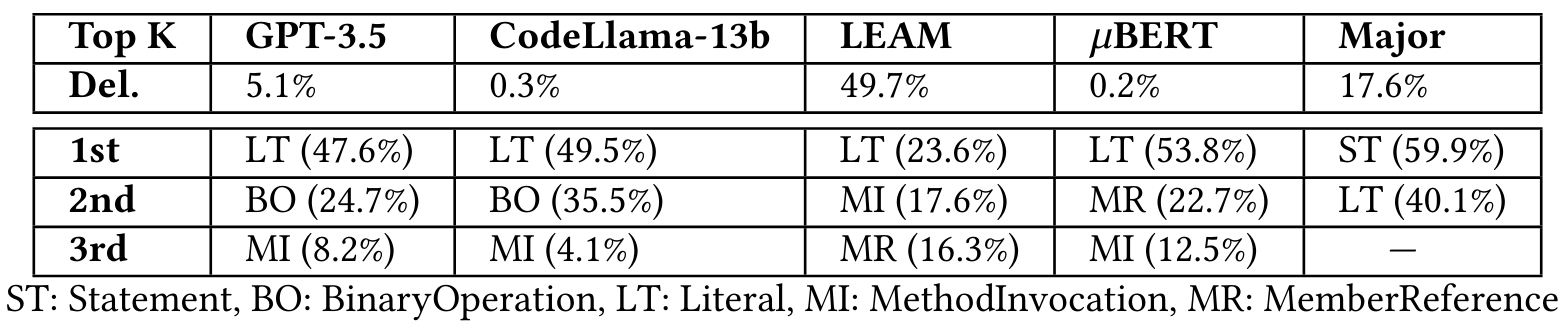
We further analyzed the distribution of deletions and AST Node types across different approaches, as shown in Table 6, which highlights the top-3 most frequent AST node types. For the proportion of deletions, GPT-3.5 and CodeLlama-13b generate 5.1% and 0.3% deletions, respectively. Nearly half of the mutations of LEAM are deletions, which may be the reason for generating many non-compilable mutations. Major generates deletions on restricted locations and results in 17.6% deletions. 𝜇Bert replaces the masked code elements with BERT, thereby rarely having deletions.
garding AST Node types, the most frequent new AST node type of all the learning-based approaches is Literal (e.g., 𝑎 > 𝑏 ↦→ true). However, for the rule-based approach Major, the most frequent node type is Statement (e.g., replacing a statement with an empty statement). Note that although these mutations are not with the Deletion operator, there exists a significant portion of producing empty statements, leading to a large proportion.

This paper is
[1] Although GPT-3.5 and CodeLlama-13b are instructed to generate the same number of mutations, they do not consistently follow the instructions, thereby yielding different numbers of mutations.